For anyone working on WordPress sites, the dreaded message that WordPress requires FTP credentials to add a plugin or remove one will come up. Or that theme files can’t be edited.

Most of these stem from mismatches in file and folder ownership on your Linux server.
Typical examples would be images or files uploaded directly to the server rather than via WordPress, such as when restoring a backup while logged in as the ROOT user. WordPress tends to run as the Apache user, which means WordPress then cannot edit the files or delete them.
What is needed is to change ownership from the current owner, to the Apache user (or whichever user & group Apache runs as):
# sudo chown apache:apache /var/www/html -RThis instructs Linux to change ownership with the chown command, to the user apache, in the group apache at the specific file / folder location (/var/www/html, the normal web directory for RHEL/Centos). The flag ‘-R’ means recursive, so the command will be applied to all files in the specified folder, and all subfolders and files.
However, doing this manually will be forgotten at some point, so a better solution is to automate it with a cron job. Cron jobs are tasks that run on a specified schedule in Linux.
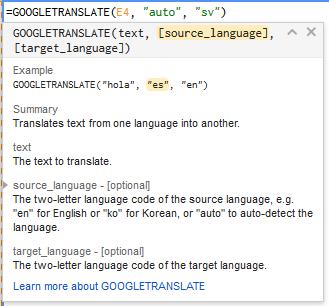
Cron jobs are usually located at /etc/crontab but some Linux distributions put it elsewhere. So we’ll make a cron job running every hour by placing only one of the below instructions into the file at the bottom:
0 \* \* \* \* chown apache:apache /var/www/html -R >/dev/null 2>&1@hourly chown apache:apache /var/www/html -R >/dev/null 2>&1This will now run your command every hour once the file is saved. The >/dev/null 2>&1 end of the command means any output will be silenced, so you’re not getting alerted each time the cron job runs. It will also mean errors won’t be communicated.
For Shared Hosting
You may not have access to the crontab or a cron job manager if you’re on a shared hosting plan, but there are other fixes which can be applied to WordPress.
You should be able to edit your wp-config.php file (in the www home directory).
Insert the following code at the end of file:
/** Sets up 'direct' method for WordPress to enable update/auto update with out FTP */
define('FS_METHOD','direct');
Once that’s saved, WordPress should now be able to update itself and plugins without errors, and also install and delete plugins.
Non-Wordpress Sites
The chown fix will work on any website with the same type of file permissions issue, as it’s likely the Apache user isn’t the file owner.
More on Cron Jobs
Linode has a good article about how cron jobs work. And Crontab.guru has a huge list of example cron job commands.