This is an aide memoire for myself, but if you have found really useful Screaming Frog tips to get the most out of the tool, please leave a comment or email me at hello@jacknorell.com.
If I include the tip, you’ll get a link back to your blog or Twitter handle.
Find unlinked mentions
If you have a long list of URLs where your brand or product is mentioned, and you want to find out which pages do or don’t link back to you, this custom filter in Screaming Frog will be useful:
<a [^>]*?href=(“|’)?http(?:s)?://(?:www\.)?YOURSITE\.com[^>]*?>
(updated to better match a link tag)
Go to Configuration and select Custom, then enter like this:
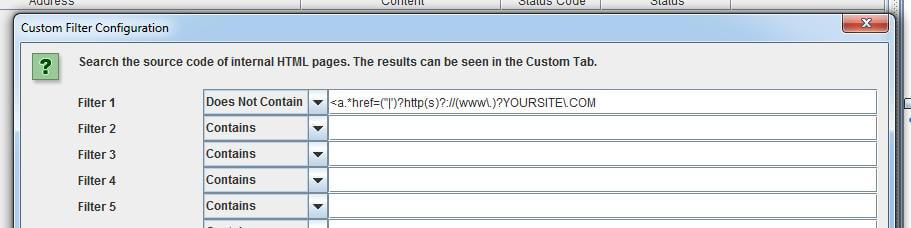
Check if page is linking to your site
By using “Contains” in the Custom settings, the filter will find if the page is currently linking to your site, though in this version not whether it is nofollowed.
If you have a modified RegEx to check for nofollow links, please do share in comments.
Match anything including New Lines with RegEx
Within Screaming Frog, the expression .* matches everything except new lines and returns, so if the HTML you want to match looks like this:
<div name=”examplediv”>
<span>Extract This Text</span>
That default expression won’t work. However, if you use (?s).* instead, it will work just fine.
Regex for Inclusion or Exclusion must match full URL string
Screaming Frog only reliably matches on the full URL evaluated. This means that this regex won’t work in all cases:
/\d{12}$
What this would normally do is include or exclude all auction listing pages on Ebay.co.uk that look like:
https://www.ebay.co.uk/itm/%5Bauction-name%5D-/141736421954
That regex should match the twelve-digit auction ID number ending the URL. However, a range of these will still be included when crawling. Updating the regex to the following, to evaluate the whole URL, will work:
.*/\d{12}$
Extract anchor text from links to a site
This is a bit messy, but if a page is linking to example.com, it will extract the text from ‘example.com’ to the next closing anchor tag </a>.
This may at times capture other HTML tags that wrap the anchor text itself inside the <a> tag, if those tags have spaces before or after as the regex currently does not handle spaces well. You can find these easily by running a =find(“<“, [cell reference]) to locate any tag opening sharp brackets, then clean up manually.
href=.*?example\.com.*?>(?:<.*?>)*?(.*?)(?:<.*?>)*?</a>
Note that only the first link’s anchor text will be extracted. If the page has more than one link to example.com, you will need to use a script to break up the page source code and iterate through the resulting text strings.
If you have a more sophisticated working example, please share in the comments.
This Screaming Frog tips article is regularly updated
More Screaming Frog tips & tricks will be added over time.
Is this also applicable for free users?
Hi Cris
The Custom Extraction and API features (i.e. Google Analytics integration) are both paid user features only.
The software is very much worth the annual fee however, and I’d encourage anyone to buy their own copy.
Jack