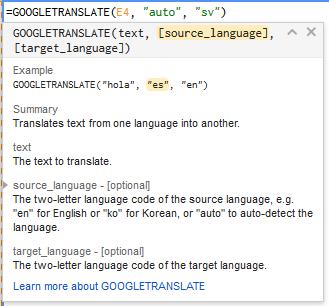
WordPress, especially in version 5+, is an amazing piece of software. However, in certain situations the default code falls short. Recently, I needed to set up WordPress behind a reverse proxy, parallel-host a staging server, and use both a visual page builder and a javascript-based translation plugin.
And all of it needed to be easy-to-use for non-technical client marketing staff.
In short: A complicated setup.
The client should be able to edit and post content in a simple way, which isn’t possible in a reverse proxy setup when using a page builder. This is because the WP_HOME setting (i.e. the homepage URL) will direct any navigation from the hosting server to the public URL, the one we’re marketing to customers as well as doing SEO for. And neither our page builder or the translation plugin will work from the public domain!
I also needed the client’s web team to be able to backup and restore the site in a somewhat user-friendly way.
The code isn’t complicated to set up once it was tested in a few variations to see what worked best. Please note this doesn’t cover any Apache or nginx settings to set up the reverse proxy, as configuring and troubleshooting is best left to a hosting specialist. No special settings were needed on a typical LAMP stack for this custom code to work.
Full code at the end.
Why Modify wp-config.php?
The config file for WordPress is the most reliable place to put custom configs as it doesn’t get overwritten by WP updates, and any code here is executed before any HTML output. This is important as cookies and headers must be set before any HTML is sent to the browser.
It also executes very quickly, as WP loads files in this order:
- index.php
- wp-blog-header.php
- wp-load.php and template-loader.php
- wp-config.php loaded by wp-load.php
URL Settings
The setup only requires 3 values to be set. First we need to know the public homepage URL ($public_url), which is the front-end of our reverse proxy. This is a fully qualified URL.
Then we need the actual hosting domains for $production_server (production.example.com) and $staging_server (stage.example.com) servers. These use subdomains but could easily be domain1.com and domain2.com with no changes.
We’re not qualifying these URLs as the PHP server variable we’re going to check isn’t itself fully qualified, and there’s no reason to check against https vs http URLs, which our CDN (Cloudflare in this case) handles for us.
/* Staging and reverse proxy settings */
$public_url = 'https://public-server.com';
$production_server = 'production.example.com';
$staging_server = 'stage.example.com';
Setting and Removing Our Cookie
Mmmmm, cookies :-)
To set the cookie controlling our define( ‘WP_HOME’, “https://[www.example.com]” ); WordPress setting, we need to pick an arbitrary URL path to check for.
In this case, the parametric /?cookiesetter.
If the PHP $_SERVER variable matches, we execute the cookie setting code, then redirect with a 302 to the /wp-admin/ directory on our production server. A 302 redirect is used as the browser will remember 301 URLs in many cases, and may skip loading the requested URL and so the cookie isn’t set.
WordPress will automatically redirect to /wp-login/ if our visitor isn’t already logged in.
Note that we have ‘https://’ hardcoded in this redirect target, as we don’t want to risk a non-secure login page showing for a WordPress user.
We’re setting a cookie valid for 8 hours to match a working day. 3600 is one hour in seconds.
if($_SERVER['REQUEST_URI'] == "/?cookiesetter"){
setcookie("admincookie", 'exists', time()+3600*8, '/', $production_server, true, true); /* expire in 8 hours */
header("Location: https://$production_server/wp-admin/", TRUE, 302);
exit;
}
Removing the cookie is usually not needed, as we can go to the $public_url to see any changes made to the website, but it’s added as an option.
Again, we use a specific URL path – /?cookieremover – to trigger the code execution, give our cookie lifespan a negative number (this removes a cookie) and redirect to the homepage with ‘/’. We’ve not added the protocol (https://) as it doesn’t matter in this case.
if($_SERVER['REQUEST_URI'] == "/?cookieremover"){
setcookie("admincookie", '', time()-3600, '/', $production_server, true, true); /* expired, removes cookie */
header("Location: /", TRUE, 302);
exit;
}
Optionally, we could have redirected to the $public_url.
Staging Server Settings
Our staging server needs to set both WP_SITEURL and WP_HOME to itself so resources and internal links are self-referencing. In other words, how WordPress would work by default. This section ensures that should we take a backup from either stage or production and apply this to the other server, we’re executing the correct code.
Additionally, we need to keep the staging server out of the search engines’ indexes, so we set a new header with PHP to noindex all pages and resources on the staging server.
if($_SERVER['HTTP_HOST'] == 'staging_server'){
define( 'WP_SITEURL', "https://$staging_server" );
define( 'WP_HOME', "https://$staging_server" );
header("X-Robots-Tag: noindex, nofollow", true);
}
Production Server Settings
This is where the dynamic handling of our two WP settings have a direct effect on the front end as experienced by the WordPress user. Effectively, we’re going to ensure anyone editing the site stays on the actual hosting server rather than directed to the $public_url and unable to do edits.
First, check we’re not on the staging server.
Note that we can’t* check for the production server, as the server will always see itself in the HTTP_HOST URL. The server does not see the $public_url without modifying headers such as x-forwarded-for. Similarly, the SERVER_NAME value also remains the same, and relies on server setup, rather than hosting location.
* OK, can’t is a strong word here. We could, but it would involve significantly more setup and testing from the client’s web team, and I want to minimize this.
Then, we check for our set cookie, and if available, set both WP_SITEURL and WP_HOME to the $production_server value. If not available, we set the WP_HOME variable to our $public_url.
Now, our user will see all internal links on the site point to $production_server/[path]. A user without this cookie would follow internal links to $public_url/[path], switching to the ‘real’ domain name we’re promoting.
if($_SERVER['HTTP_HOST'] != $staging_server ){
if(isset($_COOKIE['admincookie'])){
define( 'WP_SITEURL', "https://$production_server" );
define( 'WP_HOME', "https://$production_server" );
} else {
define( 'WP_SITEURL', "https://$production_server" );
define( 'WP_HOME', $public_url );
}
}
Optionally, we could set the WP_SITEURL to our $public_url as well. Normally, the hosting server should serve resources faster than the reverse proxy server as an intermediate step for each request is removed. If using a CDN, test which performs better in your case.
Now we have a setup with wordpress behind a reverse proxy, a staging server which behaves correctly, and the client is able to edit, publish, backup and restore the site with a good level of user-friendliness.
Why not Check is_user_logged_in()?
The problem I encountered is that the user must be able to log in to WordPress before is_user_logged_in() is TRUE.
Unfortunately, the /wp-login/ page tends to redirect to the WP_HOME URL when submitting the login form, and so our user isn’t logged in.
Another solution we initially tested was using a list of IP addresses to control the WP_HOME and WP_SITEURL settings. This was an effective but not efficient solution that required programming skills to maintain and update each time a user connects from a new IP address.
Complete Code
Copy the following into your wp-config.php at or near the top to implement this solution. It should work fine once updated with your site’s settings, let me know if it doesn’t and I’ll try to help.
/* Staging and reverse proxy settings */
$public_url = 'https://public-server.com';
$production_server = 'production.example.com';
$staging_server = 'stage.example.com';
/* Staging and reverse proxy code */
if($_SERVER['REQUEST_URI'] == "/?cookiesetter"){
setcookie("admincookie", 'exists', time()+3600*6, '/', $production_server, true, true); /* expire in 6 hours */
header("Location: https://$production_server/wp-admin/", TRUE, 302);
exit;
}
if($_SERVER['REQUEST_URI'] == "/?cookieremover"){
setcookie("admincookie", '', time()-3600, '/', $production_server, true, true); /* expired, removes cookie */
header("Location: /", TRUE, 302);
exit;
}
if($_SERVER['HTTP_HOST'] == 'staging_server'){
define( 'WP_SITEURL', "https://$staging_server" );
define( 'WP_HOME', "https://$staging_server" );
header("X-Robots-Tag: noindex, nofollow", true);
}
if($_SERVER['HTTP_HOST'] != $staging_server ){
if(isset($_COOKIE['admincookie'])){
define( 'WP_SITEURL', "https://$production_server" );
define( 'WP_HOME', "https://$production_server" );
} else {
define( 'WP_SITEURL', "https://$production_server" );
define( 'WP_HOME', $public_url );
}
}
Photo by Lavi Perchik on Unsplash